While developing any test automation framework we should keep in mind few key attributes as outlined below:
Monday, 10 September 2018
Tuesday, 10 July 2018
XPath for Selenium WebDriver
When automating any web application with Selenium you will come across page elements for which there is no unique id or name. Locating by class name or tag name can rarely be used as those will return multiple elements in a page. Locating by link text works only for links (<a> tags). In such scenarios XPath is the locating technique which comes for the rescue. You can literally locate any element in your web page using XPath no matter where on the page the element appears and whether the element contains any attribute or not.
Here are the scenarios where XPath can be used:
- Locating elements with standard attributes [id, name, class, etc]
- Locating elements with non-standard attributes which are specific to your web page
- Locating elements with partial attribute name
- Locating elements with displayed text or part of displayed text
- Locating elements relative to a known element
XPath can be absolute or relative. For absolute xpath always starts at the root html tag and you need to specify each and every tag that comes in between the html tag and the element you want to find. Lets consider below html snippet:

The absolute xpath to locate the highlighted "input" element will be:
/html/body/div[1]/div[1]/form/input[@name='q']
The xpath string will keep on getting longer for the elements which does not appear at the top of the page and any addition or removal of tags in between will break the xpath. For this reason one should never use absolute xpaths.
The relative xpath syntax is similar to absolute xpath but it starts with // and doesn't need to be started with the "html" tag. Relative xpath for the same "input" element will be:
//input[@name='q']
Locating elements with attributes:
The xpath syntax for locating elements by attributes is:
//tagName[@attributeName='attributeValue']
Examples:
//input[@name='q'] - will find the "input" element having name attribute 'q']
//*[@id='query'] - will find any element having id attribute 'query']
Multiple attributes can also be used together as below:
//input[@name='q'][@class='textfield']
Locating elements with partial attribute name
You may come across scenarios when the attribute value is not static and it changes from one context to another. Lets consider the below snippet where the title of the logout link also contain the user name:

One thing that is common in the above two cases is that the title attribute contains "logOut" in the attribute value. The xpath for the logout link which will work for both the users is as below:
//a[contains(@id,'logOut')]
"contains" here is called a xpath function and it checks the attribute 'id' contains 'logOut' in the value.
Locating elements with displayed text or partial text
You will come across elements which doesn't contain any useful attribute but there is a displayed text. Consider the below html snippet:
//div[text()='A testing framework for the JVM']
Suppose we don't want to specify the whole displayed text to locate the element, we want to use part of the displayed text. We can combine text() with contains() to achieve this as below:
//div[contains(text(), 'A testing framework for the JVM')]
Locating elements relative to a known element using xpath axes
In scenarios when the element you want to locate doesn't have any useful attribute or displayed text to identify, the only option left is to locate the element relative to a known element. Xpath is the only locating technique which can be used to locate related elements at any level in the html DOM. There are thirteen different axes in xpath as listed in the below table. The highlighted ones are the most frequently used and almost any element in your web page can be located using those only.
Axis name
|
When to use
|
ancestor
|
To
select all ancestors (parent, grandparent, etc.) of the current node
|
ancestor-or-self
|
To
select all ancestors (parent, grandparent, etc.) of the current node and the
current node itself
|
attribute
|
To select all
attributes of the current node
|
child
|
To select all
children of the current node
|
descendant
|
To select all
descendants (children, grandchildren, etc.) of the current node
|
descendant-or-self
|
To select all
descendants (children, grandchildren, etc.) of the current node and the
current node itself
|
following
|
To select everything
in the document after the closing tag of the current node
|
following-sibling
|
To select all
siblings appearing after the current node
|
namespace
|
To select all
namespace nodes of the current node
|
parent
|
To select the
parent of the current node
|
preceding
|
To select all
nodes that appear before the current node in the document, except ancestors,
attribute nodes and namespace nodes
|
preceding-sibling
|
To select all
nodes that appear before the current node in the document, except ancestors,
attribute nodes and namespace nodes
|
self
|
To select the
current node
|
Lets see how the highlighted xpath axes can be used to locate elements in a html grid.

Xpath axis syntax:
The syntax for using xpath axis is:
//knownXpath/axisName::elementName
Example 1:
Get the grid row ("tr") for employee name "Pradip Patra"
//td[text()='Pradip Patra']/ancestor::tr
or
//td[text()='Pradip Patra']/parent::tr
Example 2:
Get the checkbox for the grid row for employee name "Pradip Patra"
//td[text()='Pradip Patra']/parent::tr/td[1]
And this is how the xpath is built:
- Get the "td" with text "Pradip Patra"
- Go to the parent "tr"
- Get the first "td" child of the above "tr" [td[1] indicates that the position of the located "td" is at position 1]
Al alternative xpath for the above scenario using "preceding-sibling" can be:
//td[text()='Pradip Patra']/preceding-sibling::/td[1]
Example 3:
Get the position [CEO] of "Advik Patra"
//td[text()='Advik Patra']/following-sibling::td
Thursday, 10 May 2018
Automated Acceptance Testing using Cucumber-JVM
This post will give a quick introduction to Cucumber-JVM and an easy-to-follow tutorial to start using Cucumber for writing and automating features.
Quick introduction to Cucumber
Cucumber is a BDD (Behavior Driven Development) framework originally written for Ruby. Cucumber-JVM is the pure Java implementation of Cucumber. Its quite matured now and has almost all the features available in original Cucumber implementation. Cucumber is less a test automation tool and more a collaboration tool between the business and technology people in the team. Cucumber supports describing the behavior of your system in a domain specific natural language called Gherkin. Cucumber features files written in Gherkin syntax act as documentation as well as automated acceptance tests.
How does a Cucumber feature looks like?
Feature: Title of your feature
In
order to <meet some goal>
As a
<type of stakeholder>
I
want <a feature>
Scenario: Title of the first scenario
Given <some context or precondition>
And <additional precondition> optional
When <some action is performed>
Then <some result or post condition>
And <additional post conditions> optional
Scenario: Title of the second scenario
...........
..........
How does it work?
Once the behavior of a system is written in feature files like above by the business/solution analysts, developers/test engineers will write the underlying glue code (or step definitions) to actually test the system. The glue code can be direct calls to application code or calls to other libraries/APIs (like WebDriver, RestAssured, etc) depending on the application and type of test.
In this blog we are going to write and automate acceptance tests using Cucumber and Selenium WebDriver for a simple WikiPedia search functionality.
Create and configure your project in Eclipse
Create a new Maven project in Eclipse with below details:
Archetype: maven-archetype-quickstart
Group Id: com.cucumber
Artifact Id: learncucumber
Your project structure in "Package Explorer" will look like below:

Add a new source folder "src/test/resources" in the project and then add a new folder named "features" under this source folder. Your project will now look like below:

Now edit the pom.xml, add below two dependencies and save the pom.xml:
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/info.cukes/cucumber-java -->
<dependency>
<groupId>info.cukes</groupId>
<artifactId>cucumber-java</artifactId>
<version>1.2.5</version>
</dependency>
All the required jars for Cucumber and WebDriver will be downloaded. Now add a new folder named "drivers" in "src/test/resources" source folder, download and place "chromedriver.exe" in this folder. Project will look like below:

Now the project is ready to add our first feature file and automate it.
Add a new feature file
Before we add our first Cucumber feature file, we need to install cucumber-eclipse plugin from update site https://cucumber.io/cucumber-eclipse/update-site
Add a new file named "SearchCountry.feature" in the "src/test/resources/features" folder. The cucumber-eclipse plugin will create the SearchCountry.feature file with an example Gherkin feature file as shown below:
Add a new file named "SearchCountry.feature" in the "src/test/resources/features" folder. The cucumber-eclipse plugin will create the SearchCountry.feature file with an example Gherkin feature file as shown below:

Change the content of the file to below text:
#This
feature enables a user search for country names
Feature:
Search for country names
In order to know about few countries
As a user
I want to search few country names
#First
scenario
Scenario:
Search for an Asian country
Given I am on Main Page
When I search for country "India"
Then I verify "India" displays in the header
In the eclipse IDE all of the above three steps will appear in a yellow color (with warning sign) indicating the steps do not have matching glue code as shown below.

Right click on the feature file in the editor and "Run As" Cucumber Feature. Once run, the console will print below log:
1 Scenarios (1 undefined)
3 Steps (3 undefined)
You can implement missing steps with the snippets below:
@Given("^I am on Main Page$")
public void i_am_on_Main_Page() throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@When("^I search for country \"([^\"]*)\"$")
public void i_search_for_country(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Then("^I verify \"([^\"]*)\" displays in the header$")
public void i_verify_displays_in_the_header(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
Write the glue code (step implementation)
Create a new java class named "WikipediaStepDefinitions" in the "com.cucumber.learncucumber" package of "learncucumber/src/test/java" source folder and copy and paste the code snippets from console. Save the file. If you run the feature again you will see below result in console:
Feature: Search for country names
In order to know about few countries
As a user
I want to search few country names
#First scenario
Scenario: Search for an Asian country # C:/workspace/cucumber/learncucumber/src/test/resources/features/SearchCountry.feature:7
Given I am on Main Page # WikipediaStepDefinitions.i_am_on_Main_Page()
cucumber.api.PendingException: TODO: implement me
at com.cucumber.learncucumber.WikipediaStepDefinitions.i_am_on_Main_Page(WikipediaStepDefinitions.java:17)
at ?.Given I am on Main Page(C:/workspace/cucumber/learncucumber/src/test/resources/features/SearchCountry.feature:8)
When I search for country "India" # WikipediaStepDefinitions.i_search_for_country(String)
Then I verify "India" displays in the header # WikipediaStepDefinitions.i_verify_displays_in_the_header(String)
1 Scenarios (1 pending)
3 Steps (2 skipped, 1 pending)
Feature: Search for country names
In order to know about few countries
As a user
I want to search few country names
#First scenario
Scenario: Search for an Asian country # C:/workspace/cucumber/learncucumber/src/test/resources/features/SearchCountry.feature:7
Given I am on Main Page # WikipediaStepDefinitions.i_am_on_Main_Page()
cucumber.api.PendingException: TODO: implement me
at com.cucumber.learncucumber.WikipediaStepDefinitions.i_am_on_Main_Page(WikipediaStepDefinitions.java:17)
at ?.Given I am on Main Page(C:/workspace/cucumber/learncucumber/src/test/resources/features/SearchCountry.feature:8)
When I search for country "India" # WikipediaStepDefinitions.i_search_for_country(String)
Then I verify "India" displays in the header # WikipediaStepDefinitions.i_verify_displays_in_the_header(String)
1 Scenarios (1 pending)
3 Steps (2 skipped, 1 pending)
This is because the only thing our implementation methods do is to throw an exception indicating that implementation of these methods are still pending. Lets complete the implementation.
We need to launch a browser before executing our scenario - the best way to do that in Cucumber is to use a separate method annotated with @Before which will be executed before each scenario execution. This is similar to using @Before in JUnit and is called a "hook" in Cucumber. We will also use @After hook to quit a browser. Final implementation of "WikipediaStepDefinitions" will be as below:
package com.cucumber.learncucumber;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import cucumber.api.java.After;
import cucumber.api.java.Before;
import cucumber.api.java.en.Given;
import cucumber.api.java.en.Then;
import cucumber.api.java.en.When;
import junit.framework.Assert;
public class WikipediaStepDefinitions {
WebDriver driver;
@Before
public void launchBrowser(){
System.setProperty("webdriver.chrome.driver", "src/test/resources/drivers/chromedriver.exe");
driver = new ChromeDriver();
}
@Given("^I am on Main Page$")
public void i_am_on_Main_Page() throws Throwable {
driver.get("https://en.wikipedia.org/wiki/Main_Page");
}
@When("^I search for country \"([^\"]*)\"$")
public void i_search_for_country(String countryName) throws Throwable {
WebElement searchField = driver.findElement(By.id("searchInput"));
WebElement searchButton = driver.findElement(By.id("searchButton"));
searchField.sendKeys(countryName);
searchButton.click();
}
@Then("^I verify \"([^\"]*)\" displays in the header$")
public void i_verify_displays_in_the_header(String countryName) throws Throwable {
WebElement headerField = driver.findElement(By.id("firstHeading"));
Assert.assertEquals(countryName, headerField.getText());
}
@After
public void quitBrowser(){
driver.quit();
}
}
Run the feature again and it will pass this time.
Make the code better
We have direct calls to WebDriver API in our "WikipediaStepDefinitions" class above. This is certainly not a good way to write your step implementation. Now lets refactor and place our WebDriver calls in PageObject classes. Refactored and improved project code is available in https://github.com/pradip79/learn-cucumber.git
Now add new scenarios to the existing feature file or add new feature file with new scenarios and automate those. Comment if you need additional info..
Now add new scenarios to the existing feature file or add new feature file with new scenarios and automate those. Comment if you need additional info..
Wednesday, 2 May 2018
Build and deploy your simple web app using Jenkins, GitHub and Tomcat
In this post we are going to create a simple "Hello World" maven web app project in Eclipse, push the project into GitHub repository, build & deploy to Tomcat using Jenkins. Lets start by creating a sample web application and placing it in GitHub.

Step 2:
Select “maven-archetype-webapp” à Click Next.

Step 3:
Enter Group Id (say "com.demo.webapp"), Artifact Id (say "mywebapp") à Click Finish.

Step 4:
Open "Git Repositories View" through Window à Show View à Other à Git à Git
Repositories à Click OK

Step 5:
Login to GitHub and create a new repository checking option "Initialize this repository with a README” as shown below.

Step 6:
Copy the repository URL clicking on Clone or download button.


Step 8:
Keep the default branch selection and click Next

Step 9:
Browse the local storage directory for the cloned repo or keep default selection and click Finish. Cloned repo will be displayed in the "Git Repositories" view.


Step 10:
Right click on your project name in eclipse à Team à Share Project.. Select the cloned repository from dropdown and click Finish.

The project will now be shared and repo name and branch name will be displayed beside project
name as shown below.


Step 12:
Right click on the Working Tree and select “Add to Index”. All the project files are now displayed under “Staged Changes” section in the staging view as shown below.

Step 13:
Enter a commit message and click Commit and Push. Enter GitHub account access details and click OK.

Click OK on the next dialog.
Step 14:





In the "Build Triggers" section check "Poll SCM" and enter H/5 * * * * in the "Schedule" text area [which will poll GitHub every 5 min]


Create a maven project and push it into GitHub
(Skip this if you already have your project in GitHub)
Step 1:
File à New à
Maven Project àClick Next in the below “New Maven Project” dialog.

Step 2:
Select “maven-archetype-webapp” à Click Next.

Enter Group Id (say "com.demo.webapp"), Artifact Id (say "mywebapp") à Click Finish.

Step 4:
Open "Git Repositories View" through Window à Show View à Other à Git à Git
Repositories à Click OK

Step 5:
Login to GitHub and create a new repository checking option "Initialize this repository with a README” as shown below.

Step 6:
Copy the repository URL clicking on Clone or download button.

Step 7:
In eclipse “Git Repositories” view click on Clone a Git
repository link. In the "Clone Git Repository" dialog paste the copied URL in the URI field, enter authentication
information and click Next.

Step 8:
Keep the default branch selection and click Next

Step 9:
Browse the local storage directory for the cloned repo or keep default selection and click Finish. Cloned repo will be displayed in the "Git Repositories" view.


Step 10:
Right click on your project name in eclipse à Team à Share Project.. Select the cloned repository from dropdown and click Finish.

name as shown below.

Step 11:
Window à Show View à Other à Git à Git Staging à Click OK to open Git Staging
view. Select the “Working Tree” in “Git
Repositories” view. All the project files are displayed under “Unstaged
Changes” section in the staging view as shown below.

Right click on the Working Tree and select “Add to Index”. All the project files are now displayed under “Staged Changes” section in the staging view as shown below.
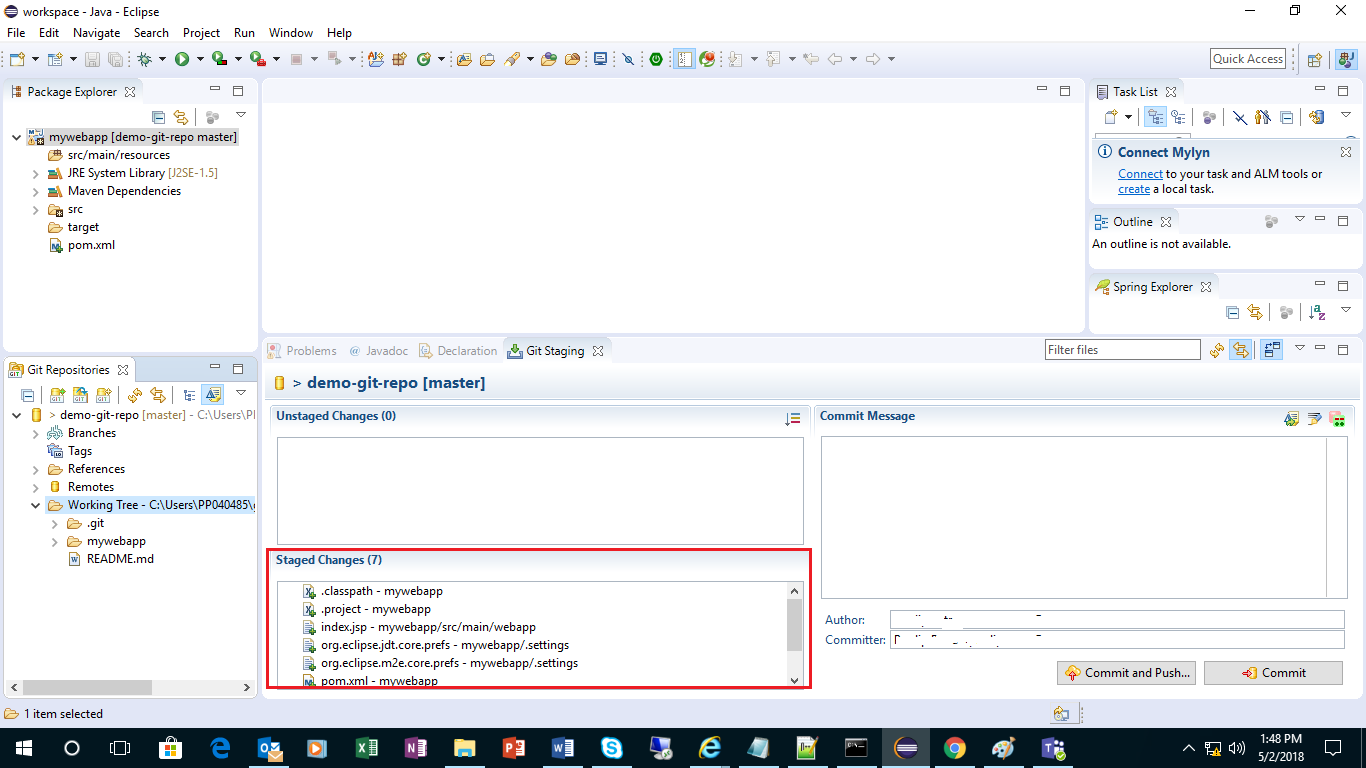
Step 13:
Enter a commit message and click Commit and Push. Enter GitHub account access details and click OK.

Click OK on the next dialog.
Step 14:
Open GitHub repository and now the project contents will be displayed there. We have our project in GitHub finally...

Add a new Maven project in Jenkins and configure it to build and deploy
Step 1:
Through "Manage Jenkins" à "Manage Plugins", install below plugins if not
already installed:
Git, GitHub, Deploy to container Plugin, Maven Integration
plugin
Step 2:
In Jenkins add a new item of type Maven project

Step 3:
In the project configuration page check “GitHub project”
checkbox and enter the GitHub repository URL as shown below:

In the “Source Code Management” section again enter the same
repository URL.
Click Add à Click Jenkins to open “Jenkins Credentials Provider” dialog as below.
Enter GitHub Username and Password, enter a description (say GitHub) and click Add

Select the newly added credentials from the "Credentials" dropdown.


In the "Build" section enter below information:
Root POM: mywebapp/pom.xml
Goals and options: clean package
In the "Post-build Actions" section enter a post-build action of type "Deploy war/ear to a container" and enter the below information.
WAR/EAR files: **/*.war
Context path: mywebapp
Container: Tomcat 8.x
Credentials: Add a new Jenkins credentials with the Username and Password of a user having tomcat "manager-script" role access.
Tomcat URL: http://localhost:8080 [Enter your tomcat URL]

Click Apply and click Save.
Step 4:
Run a new build of the newly created project in Jenkins. If the build is a "Success" open your browser and get to the URL "http://localhost:8080/mywebapp/". "Hello World!" will be displayed in the browser. We have built and deployed our new web project using Jenkins and Maven.
Step 5:
Now make some changes in our web application source code by adding "Better" to "Hello World!" in the index.jsp, commit and push the changes.
Wait for few minutes [less than 5 min] and a new Jenkins build of our project will be kicked off automatically. Once the new build gets completed refresh your browser and now "Hello Better World!" will be displayed.
Subscribe to:
Comments (Atom)